Symetrie et distribution normale
Source : https://datapeaker.com/big-data/base-de-datos-sql-vs-nosql-diferencia-entre-sql-y-nosql/
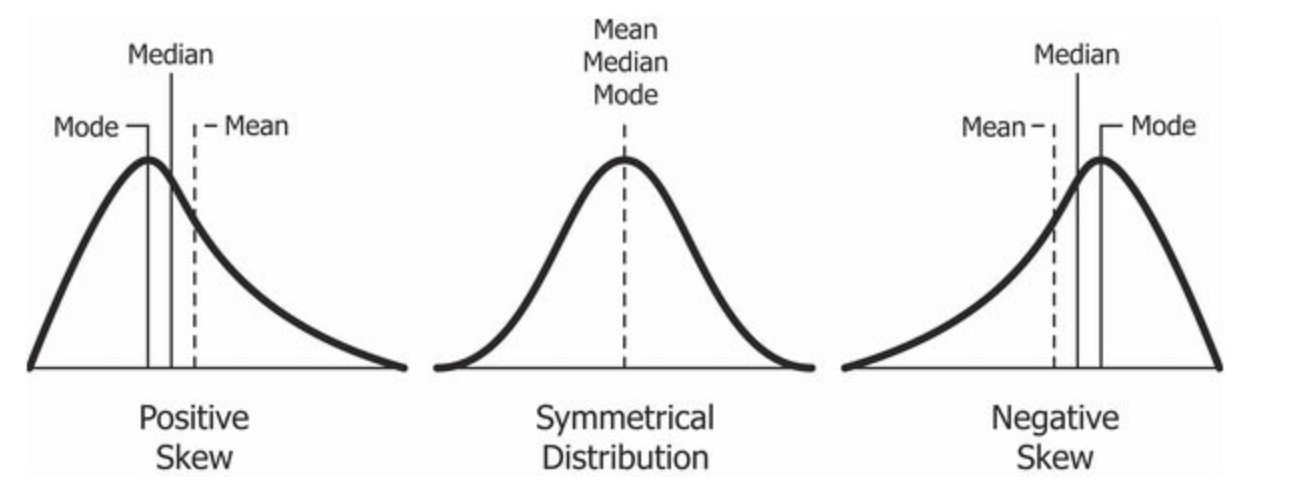
Une distribution symétrique est appelée également une distribution normale. Elle est dite « normale » car elle est utilisée pour comme référence pour déterminer l’asymetrie d’une distribution quelconque.

La symétrie d’une distribution normale peut se traduire par les caractéristiques observées sur une boîte à moustache de distribution symetrique oû on aura Q3 – Q2 = Q2 – Q1 et dont la longueur de chaque moustache est identique (voir le dessin ci-dessous).

Source : https://datapeaker.com/big-data/base-de-datos-sql-vs-nosql-diferencia-entre-sql-y-nosql/
Paramètres de la loi normale
Soit X une variable aléatoire suivant la loi normale de paramètres µ et σ.
– Son espérance est : E (X) = µ
– Son écart-type est : σ (X) = σ
– Sa variance est : V (X) = σ2
On note
X ∼ N(µ,σ2)
ou encore
X ∼ N(µ,σ)
Dans le cas où le second paramètre est noté σ2 il représente alors la variance plutôt que l’écart-type.
Propriétés de la représentation graphique
La forme de la représentation graphique de la fonction de densité d’une variable aléatoire normale est appelée courbe en cloche.
Règle des 3 sigmas
Si X une variable aléatoire suit une loi normale de moyenne 𝜇 et d’écart-type 𝜎, alors :
– P(µ-σ < X < µ+σ) = 0,683
– P(µ-2σ < X < µ+2σ) = 0,95
– P(µ-3σ < X < µ+3σ) = 0,99
Traduction :
- 68% des données se trouve entre la moyenne et 1 fois l’écart-type.
- Deux fois l’écart-type, vous regroupez 95% de vos données.
- 99% des données se trouvent entre la moyenne et trois fois l’écart-type.
Lecture graphique
Pour une bonne compréhension de cette Règle des 3 sigmas, il faut avoir en tête le schéma ci-contre:

Propriétés de symétrie et calcul de probabilité
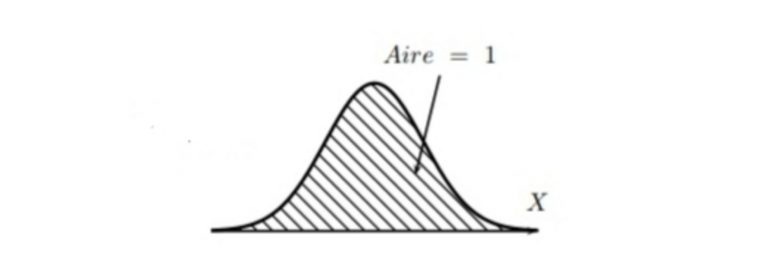
L’aire totale sous la courbe est égale à la probabilité de p=1. Cette probabilité p=1 est aussi égale à 100%.
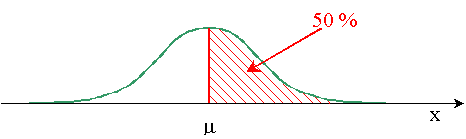
La symétrie étant parfaite, la moitié de l’aire sous la courbe contient p=0,5 soit 50%.
Autres cas de symétrie
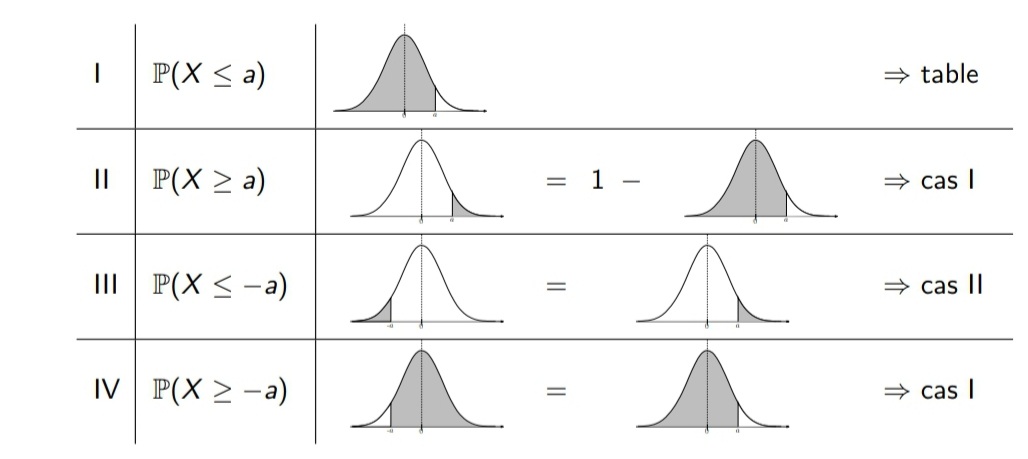
Traduction
- Si P(X < a) alors P(X > a) = 1 – P(X < a)
- P(X < -a) = P(X > a)
- P(X> – a) = P(X < a)
Loi normale et loi normale centrée réduite
Pour décrire une loi normale, on utilise la notation suivante :
X ∼ N(µ,σ2)
ou encore
X ∼ N(µ,σ)
Pour décrire une loi normale centrée réduite on utilise la notation suivante :
X∼N(0,1)
Pour faire des calculs avec une loi normale N(µ, σ), on se ramène à la loi N(0, 1).

Table de conversion
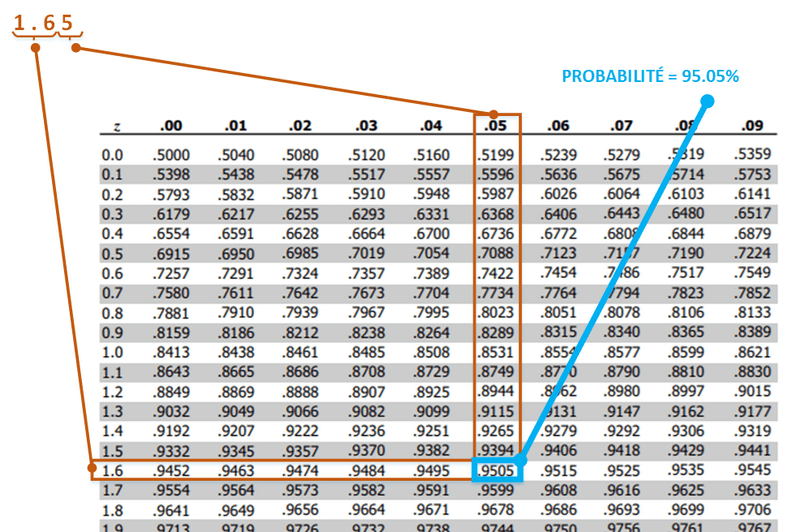
On s’entraîne
1) À quelle probabilité correspond la valeur Z – 1,68 sur la table idoine?
2) Z est une variable aléatoire qui suit la loi normale centrée réduite N(0;1).
On donne P(Z⩽1,2)≈0,885 à 10−3 près.
Déterminer sans calculatrice, à 10−3 près, P(Z⩾−1,2) puis P(−1,2⩽Z⩽1,2).




More Stories
Introduction à la Statistique Inférentielle
COURS N°7 Interprétation Des Données À Partir D’Un Histogramme
COURS N°6 Lire & Interpréter Des Diagrammes En Statistiques